
Producer und Consumer – die Anbindung der Systeme
Was wir bisher zu dem Thema veröffentlicht haben finden Sie hier:
Teil 1 - Teil 2 - Teil 3 - Teil 4 - Teil 5 - Teil 6 zu Model Driven Transformation for Streaming Applications
In diesem Betrag beschäftigen wir uns mit dem Aufbau und der Anbindung der Producer- und der Consumer-Applikation.
Vision
Nicht immer können die bestehenden Systeme direkt auf Apache Kafka umgestellt werden. Manchmal muss man sich der Integration mittels Servicefassaden bedienen. Daher werden exemplarisch zwei Komponenten mit Spring entwickelt, welche mittels REST-Service den Zugriff auf Kafka ermöglichen. Auf diesen Weg sollen im Anschluss auch die Integrationstests der gesamten Kette an Komponenten und Aufrufen erfolgen.
Unsere Lösung
Ein Überblick der beteiligten Komponenten zeigt Abbildung 1. Hier sind die drei Komponenten unserer Architektur gut zu erkennen. Producer, StreamMapper und Consumer. Da dem StreamMapper als Kernkomponente ein eigener Beitrag zuteil wird, liegt der Fokus auf dem Consumer und dem Producer.
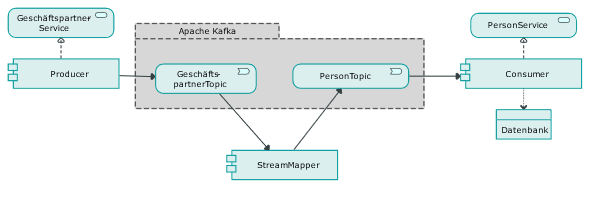 Abb.1: Überblick der Software
Abb.1: Überblick der Software
Producer
Der Producer ist als REST-Controller konfiguriert, welcher die Daten in den Geschäftspartner-Topic einspeist. Unter Verwendung des Spring-Frameworks lässt sich die Kommunikation sehr kompakt verwirklichen. Das zeigt sich am Beispiel der implementierenden Java-Klasse, welche nur wenige Zeilen umfasst und in der viele Funktionalitäten mittels Java-Annotationen erreicht werden können.
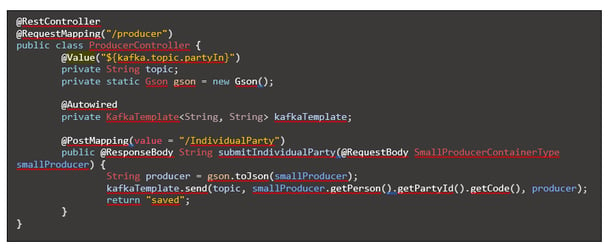
- @RestController: zeigt dem SPRING-Framework an, dass diese Klasse SPRING-spezifische Methoden zur Verfügung stellt.
- Web-Requests werden ebenfalls per Annotation auf Java-Funktionalität abgebildet. Bei einem Request mit dem Pfad „…/producer/IdividualParty“
- würde die Annotation @RequestMapping("/producer")die Klasse als zuständig kennzeichnen und
- @PostMapping(value = "/IndividualParty" die entsprechende Methode.
- @Value("${kafka.topic.partyIn}") sorgt dafür, dass der Name des Topics per Value-Injection aus der Konfigurationsdatei ‚application.yml‘ herangezogen wird.
Die Kafka-interne Serialisierung von Datumswerten warf allerdings einige Probleme auf. Mit Hilfe des GSON-Frameworks findet sich für unser Beispiel aber eine ebenfalls sehr gute und kompakte Alternative:
- private static Gson gson = new Gson();
- String producer = gson.toJson(party);
Consumer
Der Consumer ist der Empfänger der gemappten Daten unserer Mapping-Infrastruktur. Er bietet ebenfalls einen REST-Service zum Abrufen der gemappten Daten an. Dieser kann zu Testzwecken über die integrierte Swagger-UI genutzt werden, was das manuelle Testen erheblich vereinfacht.
Für den Consumer sind grundsätzlich zwei alternative Varianten möglich, wie mit der Queue interagiert wird:
- Pull: Hier wird beim Serviceaufruf einfach auf die Queue zugegriffen, den oder die nächsten Datensätze geholt und diese zurückgegeben. Diese Variante ist am wenigsten fehleranfällig. Schließlich sind hierbei keine weiteren Komponenten beteiligt. Für die Integration zwischen verschiedenen Systemen ist dies das Mittel der Wahl, wenn eines der Systeme die Daten nach dem Pull-Prinzip vom Service via Polling holt. Andere Integrationsformen, wie etwa das Einspielen nach dem Push-Prinzip in ein anderes Softwaresystem - sei es via Service (REST, SOAP, Corba etc.) oder automatisierten Dateiimport - ist hier nur mittels zeitgesteuerter batch-Jobs möglich. Schneller geht es jedoch mit Integrationsvariante 2.
- Push: Nutzt man Kafka so wie gedacht, so lässt man sich die die Daten direkt zustellen. In diesem Fall kann die Integrationskomponente direkt darauf reagieren, indem sie z.B. einen SOAP-Service aufrufen, um die Daten in das andere Softwaresystem einzuspielen. Somit können die Daten zeitnah an andere Systems verteilt werden.
Variante 2 ist in den meisten Fällen das Mittel der Wahl und soll im Weiteren behandelt werden.
Also auf geht’s:
Die Zustellung der Daten lässt sich mittels Kafka-API sehr bequem implementieren. Mit @KafkaListener wird angegeben, auf welches Topic reagiert werden sollt. PayloadDAO erbt vom Spring Data CrudRepository und bietet damit die wesentlichen Speicherfunktionen von Haus aus an. Suchparameter werden aus dem Payload extrahiert – in diesem Fall die ID. Diese wird als Schlüssel benötigt, um im REST-Service auf die Daten zuzugreifen. Zusätzlich werden noch TOPIC und der json-Payload persistiert. Erweiternd kann später noch eine Versionsnummer aufgenommen werden, wenn sich das Objekt häufiger ändern sollte.
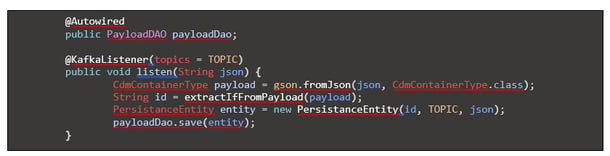
Doch woher weiß Spring, wo der Kafka-Server liegt und in welchen abständen die Daten abgerufen werden sollen. Hierfür wird eine KafkaConfiguration-Klasse benötigt:
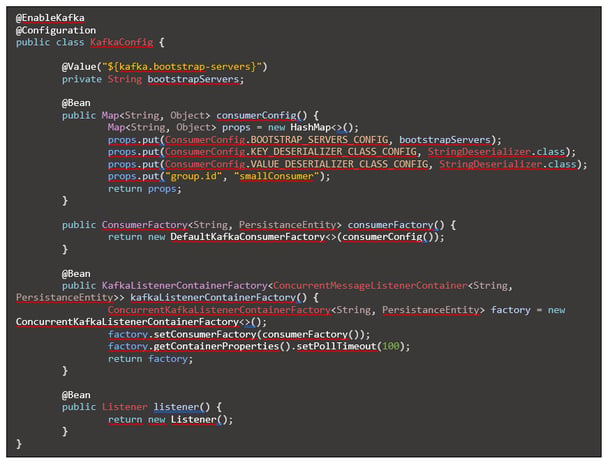
Hier sind allem drei Dinge interessant:
- Verwendung des Deserializer für Zeichenketten, da wir uns entschieden haben die Objekte selbst zu parsen.
a. props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); - Definition einer Group.id mit deren Hilfe Kafka erkennt, dass mehrere Instanzen des Services von derselben Queue laden.
a. props.put("group.id", "smallConsumer"); - Definition einer Poll-timeout, welches definiert, wie oft bzw. schnell das Topic abgerufen wird. Darüber kann eingestellt werden, wie viel Last die Komponente verträgt. Damit wird ein Fluten der Komponente verhindert und das Topic fungiert als Puffer. Im Beispiel sind 100 Millisekunden eingestellt.
a. factory.getContainerProperties().setPollTimeout(100);
Zusammenfassung
Wir haben gesehen wie wir mittels Spring einen Kafka Producer und Consumer anbinden können. Damit können Adapter entwickelt werden, welche unterschiedliche IT-Systeme über verschiedene Schnittstellen an Kafka anbinden. Beispielhaft wurde ein lesender und ein schreibender Rest-Adapter für Kafka entwickelt.
Verwenden die beiden über Kafka gekoppelten IT-Systeme unterschiedliche Datenmodelle, so ist es sinnvoll, ein- und ausgehende Queues zu trennen und mit Hilfe eines Stream-Mappers zu koppeln.
Weiterlesen:
Lesen Sie im nächsten Beitrag wie die Daten zwischen den Queues gemappt werden können.






MID Blog Newsletter abonnieren