
Datentransformation vom Producer zum Consumer
Vorwort:
Was wir bisher zu dem Thema veröffentlicht haben finden Sie hier:
Teil 1 - Teil 2 - Teil 3 - Teil 4 - Teil 5 - Teil 6 - Teil 7 zu Model Driven Transformation for Streaming Applications
In diesem Beitrag beschäftigen wir uns mit dem Daten-Mapping zwischen Producer und Consumer.
Die Challenge/Vision:
In den vorhergehenden Blog-Beiträgen wurden unter anderem zwei Ansätze beschrieben, wie die Producer- und Consumer-Daten an Kafka angebunden werden können – einmal mit Zwischenspeicher und einmal ohne.
Damit der Consumer die Daten des Producers nutzen kann, muss die Datenstruktur des Producers in die Datenstruktur des Consumers überführt werden. Hierfür muss entschieden werden, auf welchem Wege diese Datentransformation durchgeführt werden soll bzw. welche Tools hierfür unterstützen können.
Unsere Lösung:
Um die Datenstruktur des Producers in die Datenstruktur des Consumers zu überführen, standen folgende Alternativen zur Auswahl:
- Mapping mit Hilfe von JMapper (http://jmapper-framework.github.io/jmapper-core/)
- Typfreies Mapping JSON zu JSON
Mapping mit Hilfe von JMapper:
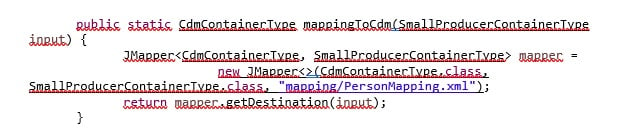
Prinzipiell ist das Mapping mit Hilfe von JMapper relativ einfach, setzt jedoch voraus, dass Quell-Typ und Ziel-Typ eindeutig definiert sind und klare Mapping-Vorschriften zwischen Quelle und Ziel existieren. Diese Mapping-Vorschriften sind in einer XML-Datei abzulegen. Das Quell-JSON-Objekt muss zudem vor dem Mapping in die Quell-Struktur und die Ziel-Struktur nach dem Mapping in das Ziel-JSON-Objekt überführt werden. Die Abbildung selbst benötigt im Code nur wenige Zeilen, wie das nachfolgende Beispiel aufzeigt:
Typfreies Mapping JSON zu JSON:
Eine Schwäche des JMappers liegt darin, dass über die XML-Konfiguration zwar 1:1-Transformationen problemlos durchführbar sind, jedoch kompliziertere m:n-Transformationen nur eingeschränkt bzw. gar nicht möglich sind. Aus diesem Grund fiel die Entscheidung auf das typfreie Streams-Mapping JSON zu JSON. Hier werden die Mapping-Vorschriften sowie Quell-Topic und Ziel-Topic, das heißt, sämtliche relevante Informationen für das Mapping in einer JSON-Datei vorgehalten. Hier ein Beispiel:

Für die Abbildung sind keine komplexen Strukturen erforderlich. Die folgenden Code-Zeilen zeigen beispielhaft, wie die Definition der Abbildung erstellt werden kann:

Der Aufruf zur Laufzeit wird wie folgt implementiert:

Fazit:
Mit Kafka ist die Datentransformation zwischen Quelle und Ziel relativ problemlos zu bewerkstelligen. Die Hauptarbeit besteht in der Erstellung der Mapping-JSON-Datei. Diese Mapping-JSON-Datei sollte idealerweise aus dem Modell generiert werden, welches die Datentransformation beinhaltet und zentral gepflegt wird.
Weiterlesen:
Im nächsten Blog wird beschrieben, wie die im Innovator modellierten Abbildungsvorschriften automatisch als JSON-Struktur generiert werden können.






MID Blog Newsletter abonnieren