
Apache Kafka – Funktionsweise, Doku, API
Was wir bisher zu dem Thema veröffentlicht haben finden Sie hier: Teil 1 und Teil 2
In diesem Betrag beschäftigen wir uns näher mit dem Stream Processing System Kafka.
Was ist Apache Kafka?
Apache Kafka - hat nichts mit Franz Kafkas „Der Prozess“ zu tun, sondern es handelt sich um eine der bekanntesten Streaming Plattformen auf dem Markt. Apache Kafka ist eine verteilte Streaming Plattform und der wohl bekannteste Vertreter der Kappa-Architektur. Kafka ist in der Lage nahezu in Echtzeit eine extrem hohe Anzahl von Daten bzw. Ereignisse in Form eines Datenstromes entgegenzunehmen, zu speichern, zu verarbeiten und bereitzustellen. Apache Kafka ist laut Confluent (https://www.confluent.io/) für zwei Einsatzszenarien am geeignetsten: zuverlässige Echtzeit-Streaming-Datenpipelines und reaktionsschnelle Echtzeit-Streaming-Anwendungen mit Datentransformation.
Aufbau von Apache Kafka
Apacha Kafka ist eine unter Java und Scala entwickelte Platform und besteht zurzeit aus 5 Haupt-APIs:
- Producer API (für schreibende Anwendungen)
- Consumer API (für lesende Anwendungen)
- Streams API (Library für Anwendungen zur Transformation von Input Daten zu Output Daten)
- Connector API (Schnittstelle für Datenimport/-export)
- AdminClient API (Managing und Controlling)
Zusätzlich stehen noch weitere APIs zur Verfügung, wie zum Beispiel die Legacy API. Siehe dazu auch die offizielle Dokumentation von Apache Kafka: https://kafka.apache.org/documentation/
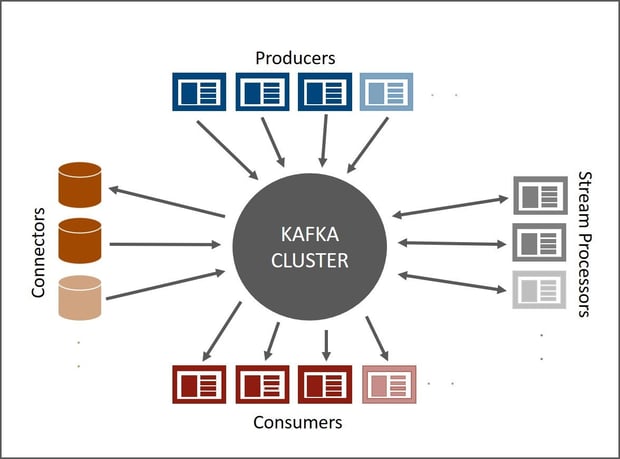
In den meisten Fällen wird Apache Kafka in einem Cluster betrieben. Jeder einzelne Knoten ist ein Broker. Die Datenströme werden innerhalb eines Clusters in Topics kategorisiert.
- Nachrichten werden auf Topics veröffentlicht
- Nachricht = Key-Value-Paar
- Jedes Topic hat konfigurierbar viele Partitionen (sortiertes, unveränderliches Protokoll mit kontinuierlich Nachrichten: das commit log
- Jeder Nachricht in einer Partition wird ein sequenzieller Schlüssel zugewiesen: das Offset (einzige Metainformation)
- Ein Broker behält jede veröffentlichte Nachricht für einen konfigurierbaren Zeitraum vor, unabhängig davon, ob diese bereits konsumiert wurde oder nicht.
- Nach Ablauf dieses Zeitfensters wird die Nachricht gelöscht
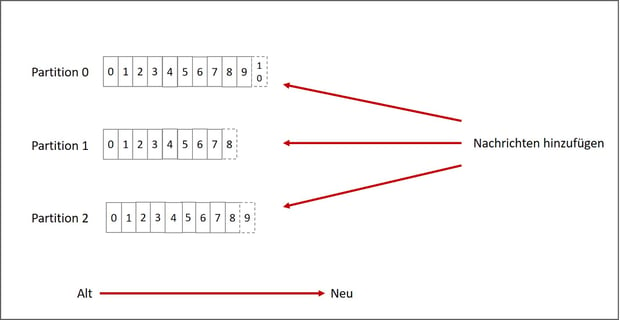
Einsatzszenarios
Apache Kafka wird unter anderem von LinkedIn, Netflix, Zalando, Pinterest und Airbnb eingesetzt.
Weiterlesen:
Im folgenden Blog-Beitrag wird es um die zugrunde liegende Software-Architektur gehen, welche den Rahmen für das weitere Vorgehen bildet.






MID Blog Newsletter abonnieren