
Fachliches Integrationsszenario und Lösungsansatz mit Kafka
Was wir bisher zu dem Thema veröffentlicht haben finden Sie hier.
In diesem Beitrag beschreiben wir die Gesamtarchitektur unseres Ansatzes auf oberster Ebene.
Die Challenge/Vision:
Aufgrund unserer Erfahrungen und Erkenntnisse bei der Arbeit mit verschiedenen Kunden haben wir als Anwendungsbeispiel zur praktischen Erprobung von Apache Kafka ein übliches Szenario aus der Unternehmenspraxis gewählt, nämlich die Datenübertragung von einem Quell-System (Producer) zu einem Ziel-System (Consumer), wobei die Daten bei ihrer Übertragung einer Transformation unterzogen werden sollen.
Der Lösungsansatz:
Für die MID als the modeling company ist ein modellgetriebener Ansatz dabei verständlicherweise die erste Wahl. Dabei werden zunächst die Schnittstellen des Quell- und Ziel-Systems in einem UML-Innovator-Modell beschrieben. Das Mapping zwischen den Quell- und den Ziel-Attributen erfolgt dabei direkt im Modell über Abhängigkeiten, anstelle der Verwendung fehleranfälliger Excel-Tabellen, die oft in der Praxis zu diesem Zweck eingesetzt werden.
Die Datentransformationsregeln können in unserem Szenario dann direkt aus dem Modell generiert werden, anstatt sie umständlich händisch mit einem Mapping-Tool zu erstellen.
Dieses Vorgehen bietet folgende Vorteile:
- Klare, nachvollziehbar dokumentierte Schnittstellen des Quell- und Ziel-Systems.
- Keine fehleranfälligen Mapping-Tabellen (in der Regel Excel), da die Abbildung von Quell- auf Ziel-Daten direkt im Modell hinterlegt wird.
- Vollautomatisches Daten-Mapping basierend auf einer aus dem Modell generierten Datentransformationsregel.
- Leichte Wartbarkeit durch modellgetriebenen Ansatz.
Die folgende Abbildung zeigt auf oberster Ebene das geplante Zusammenspiel von Innovator-Modell und den Implementierungskomponenten:
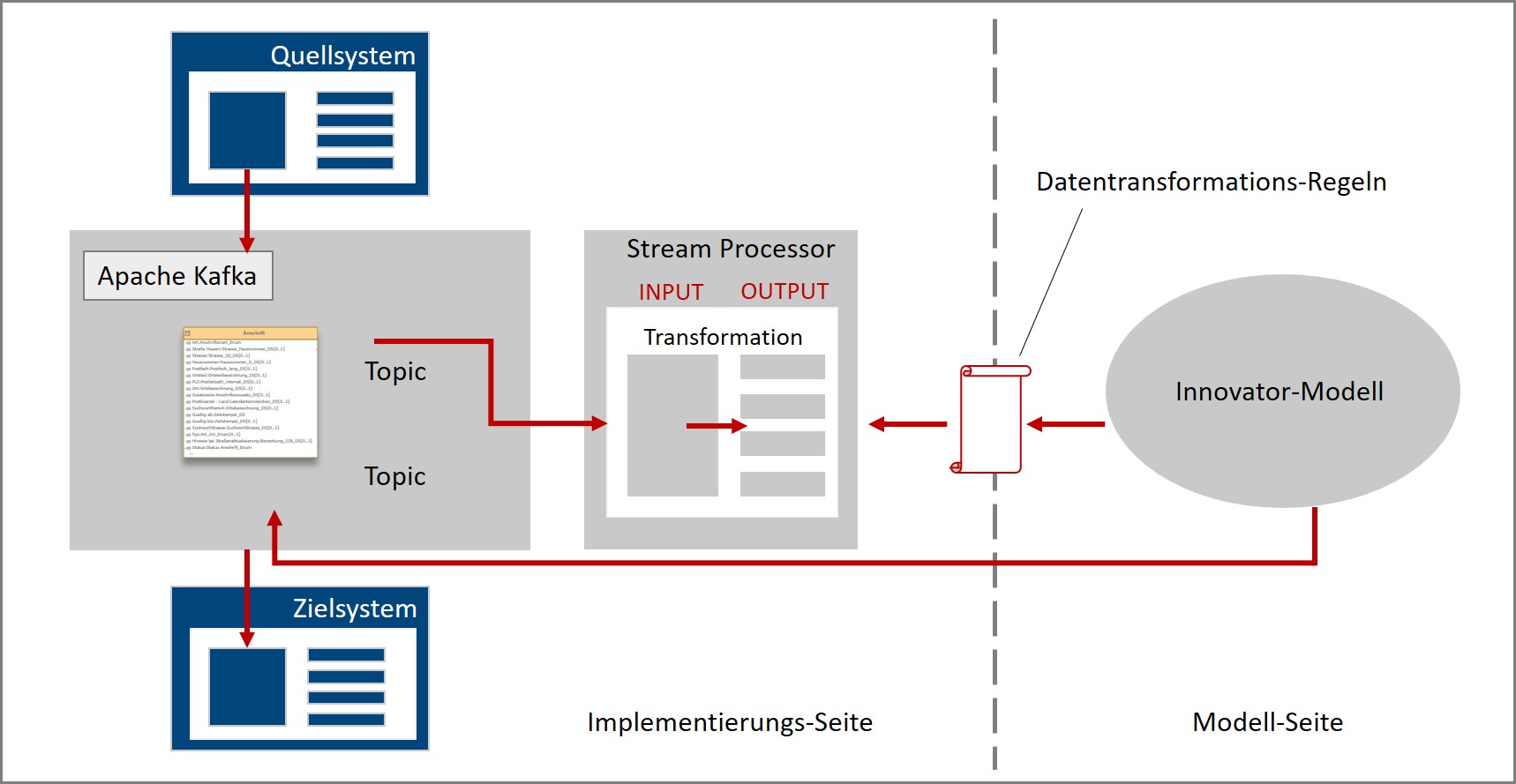
Auf der Implementierungsseite sendet das Quell-System seine Daten an Apache Kafka. Über die Apache Kafka Streaming-API werden die Daten vom Stream-Prozessor gelesen. Dort werden sie transformiert und das Ergebnis wieder an Kafka zurückgegeben. Das Ziel-System liest im Anschluss die transformierten Daten ein.
Die Transformation innerhalb des Stream-Prozessors wird durch Datentransformationsregeln gesteuert, die ihrerseits mittels eines Generators aus dem Innovator-Modell erzeugt wird.
Wie es weitergeht:
Im nächsten Blog-Beitrag wird es um die Streaming Plattform Kafka im Allgemeinen gehen, wie sie aufgebaut ist und wie sie funktioniert.






MID Blog Newsletter abonnieren