
In den vorangegangenen Blog-Beiträgen haben wir festgestellt, dass „in der schönen neuen Welt der Datenmodellierung“ das Datenbank-Schema vom konzeptionellen Schema kaum mehr zu unterscheiden ist. Jede Entität ist eine Tabelle, Denormalisierungen finden nicht statt, horizontales und vertikales Splitting ist erledigt.
Bleibt nun das mächtige Konstrukt der Generalisierung vs. Spezialisierung in der Datenmodellierung zu betrachten.
Generalisierung vs. Spezialisierung: Was bedeutet das?
Bei diesem Modellierungskonstrukt werden gemeinsame Eigenschaften von Entitäten nur einmal modelliert:
- Der Generalisierungstyp enthält die Attribute, die alle Entitäten gemeinsam haben
- Die Spezialisierungstypen enthalten die speziell für sie zutreffenden Attribute, wobei
- die Spezialisierung disjunkt oder überlappend sein kann und
- die Eigenschaften der Generalisierung erbt
Beispiele
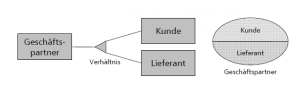
Es gibt zunächst den „IS-A-Typ“, hier wird die Gesamtmenge disjunkt aufgeteilt:
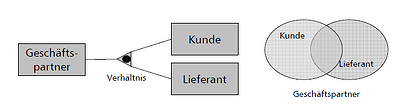
Weiter gibt es auch den „ODER-Typ“, hier wird die Gesamtmenge überlappend aufgeteilt:
Umsetzung im Datenbankdesign
Das Ganze muss nun im Datenbankdesign aufgelöst werden. Hierfür gibt es mehrere Möglichkeiten, die nachfolgend dargestellt werden.
Ausgangspunkt sind dabei die Fragen:
- Erstellt man für jede Entität eine Tabelle? ODER
- Kann bzw. muss man mehrere Entitäten zu einer Tabelle zusammenführen?
Lösung 1: Die Generalisierung ist „abstrakt“
Wenn die Generalisierung die Abbildung eines UML-Klassenmodells ist bzw. nur als Schablone dient, gilt die Generalisierung als abstrakt. Sie wird aufgelöst und in die Spezialisierungen hineingezogen.
Es ist ein ideales Modell, um einheitliche strukturierte, aber inhaltlich differierende Tabellen mehrfach zu realisieren. Das kann z.B. ein umfangreiches Klassenmodell mit kaskadierenden Generalisierungen sein, realisiert wird die am Blatt stehende Entität.
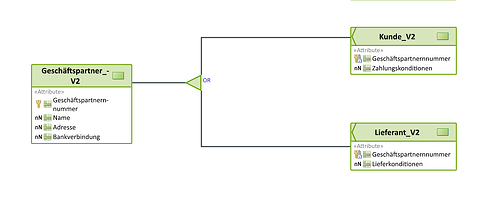
Als Beispiel ist eine einfache Vererbung dargestellt. Die Entität „Geschäftspartner“ definiert die gemeinsamen Attribute einer Geschäftsbeziehung, realisiert werden nur die Spezialisierungen, welche alle Attribute der Vaterentität erben:
.png?width=400&name=BI-Modell%20(1).png)

Lösung 2.1: Pro Entität wird eine Tabelle erstellt
Dies ist die sinnvollste und empfehlenswerte Lösung. Diese Variante ermöglicht eine in jedem Fall redundanzfreie Umsetzung des Modells. Modell und Implementierung entsprechen sich 1:1. Die Generalisierung kann als Stammtabelle aufgebaut werden und ist somit ein adäquates Hilfsmittel zur Darstellung.
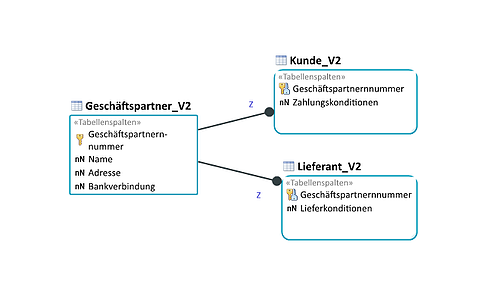
Bei unserem Beispiel würde das wie folgt aussehen: Die Generalisierung bekommt einen Primärschlüssel und kann autark realisiert werden. Die beiden Spezialisierungen werden ebenfalls als Tabelle implementiert.
Lösung 2.2: Die Generalisierung auflösen
Hier wird die Generalisierung in die Spezialisierung hineingezogen. Im Beispiel würden dann zwei statt drei Tabellen implementiert werden. Diese Variante ähnelt der Lösung 1, jedoch handelt es sich hier nicht um eine abstrakte Generalisierung.
Auf den ersten Blick ist sichtbar, dass im Falle der ODER-Generalisierung Redundanzen entstehen, da die Information der Generalisierung doppelt gepflegt werden muss.
Achtung: Diese Lösung ist somit definitiv nicht zu empfehlen. Redundante Datenhaltung ist genau das, was gute Modelle verhindern sollen.
Bewertung
Bei Generalisierung / Spezialisierung handelt es sich um ein bewährtes und vielfältiges Stilmittel der Datenmodellierung.
Für die Umsetzung ins Datenbank-Schema ergeben sich aus unserer Sicht zwei Varianten:
- Wird ein Klassenmodell umgesetzt, so werden nur die Blattentitäten als Tabelle umgesetzt
- In allen anderen Fällen wird die 1:1 Umsetzung empfohlen: Aus jeder Entität entsteht eine Tabelle
- Ein Abweichen vom konzeptionellen Schema sollte bei Generalisierungen / Spezialisierungen nur dann vorgenommen werden, wenn der Aufwand für die separate Pflege des physischen Modells mit eingerechnet ist
Mit diesem Vorgehen erhält man eine einfache, transparente, schlanke und nicht verkünstelte Umsetzung des Modells in der Datenbank.
________________________________________________________________________________________________
Weiterführende Informationen
Das Thema interessiert Dich? Dann lies den passenden Artikel zur Trennung von Datenmodellierung in konzeptionelles Schema und Datenbank-Schema oder informiere Dich, wie die Datenmodellierung von heute aussieht.







MID Blog Newsletter abonnieren