
Data Warehouse und Big Data –
Grundpfeiler eines modernen Data Hubs – Teil 1
Unter dem Motto – „Data Warehouse und Big Data – Grundpfeiler eines modernen Data Hubs“ – stellen wir Ihnen hier diese beiden Lösungen vor. Neben einer Gegenüberstellung der Unterschiede beider Welten, erhalten Sie auch eine Nutzendarstellung. Ziel ist es, das „Warum“ und „Wofür brauche ich welche Ansätze“, zu liefern.
In dieser 3-teiligen Blogserie starten wir heute mit der Definition von Data Warehouse und Big Data. Im zweiten Blogbeitrag erwartet Sie dann die Gegenüberstellung der Beiden sowie in Teil 3 eine Nutzendarstellung und möglicher Ausblick auf zukünftige Lösungsansätze.

Daten sind in Unternehmen mittlerweile ein anerkannter Vermögenswert. Um diesen Vermögenswert intelligent zu nutzen, haben sich in der Praxis konventionelle Data-Warehouse (DWH)- und moderne Big-Data-Ansätze entwickelt. Da Daten die Grundlage dieser beiden Ansätze bilden, werden sie aus einer Makroperspektive häufig gleichgesetzt. Tatsächlich nehmen sie jedoch unterschiedliche technische, fachliche und rechtliche Parameter in den Blick: Ein klassisches DWH und Big-Data-Technologien bieten also Lösungen für ganz unterschiedliche Aufgabenstellungen und Zielrichtungen eines Unternehmens. Für eine optimale Ausschöpfung der Daten und Steigerung der Konkurrenzfähigkeit ist für Unternehmen eine zielgerichtete Symbiose der Ansätze eines DWH sowie von Big Data Lösungen umzusetzen. Die Koexistenz beider Ansätze schafft eine maximale Wertschöpfung.
Definition Data Warehouse
In einem Data Warehouse werden Daten aus gleich- und verschiedenartigen Datenquellen extrahiert, transformiert und geladen Also vereinfach dargestellt, werden die Daten für eine dauerhafte Analyse gespeichert. Die so im DWH historisch gespeicherten Daten bilden den Single Point of Dataund unterstützen die Berichts- und Analysesysteme eines Unternehmens. Die ist ein zentraler Bestandteil von heutigen Business Intelligence und Business Analytics Umgebungen.
Charakteristischen Eigenschaften, die ein DWH erfüllen muss:

1. Subject-Oriented (Themenorientierung)
Während sich in operativen Systemen die Daten an den Prozessen des Unternehmens ausrichten, orientieren sich die Daten im DWH an fachlichen Themen – sogenannten Subjects. Die Konzentration auf solche Themen (Kunde, Produkt, …) ist für eine Entscheidungsfindung sehr hilfreich. Die Themenorientierung hilft auch allen Stakeholdern, Daten schnell zu finden und auszuwerten sowie interdisziplinär mittels eines einheitlichen Datenglossars zu diskutieren. Grundlage hierfür ist der themenorientierte, sachlogische Bezug der Daten.
2. Integrated (Vereinheitlichung)
Die Daten in einem DWH sind integriert. Das bedeutet, dass die Datenbestände aus den vielen unterschiedlichen Datenquellen zusammengeführt und Inkonsistenzen entfernt bzw. korrigiert werden. Auch einheitliche Namenskonventionen, Referenzdaten und physische Datentypen sowie klare Definitionen von Regeln zur Berechnung von KPIs erhöhen den Grad der Integration. Der Datenhaushalt wird somit harmonisiert und ermöglicht zusätzlich zu den obigen Punkten einen höheren Grad der Automatisierung.
3. Time-Variant (Zeitorientierung)
In einem DWH werden Daten über größere Zeiträume gespeichert als in operativen Systemen. Es ist möglich für fachliche Themen den historischen Verlauf nachzuvollziehen. Hiermit werden Analysen bzgl. Entwicklungen, Mustern und Vorhersagen unterstützt. Abfragen sind somit über aktuelle Daten (as-is) und über jeden beliebigen Zeitraum in der Vergangenheit (as-was) problemlos möglich.
4. Non-Volatile (Beständigkeit)
Daten, die einmal ihren Weg ins DWH gefunden haben, werden nicht mehr (zum Beispiel vom Anwender) verändert oder gelöscht. In einem operativen System ist dieses möglich, wenn nicht sogar notwendig. Somit sind in einem DWH per Definition alle Änderungen von Daten zu jeder Zeit nachvollzieh- und reproduzierbar.
Definition Big Data
Big Data bezeichnet eine Lösung zur Verarbeitung von sehr großen, komplexen und teilweise semistrukturierten bzw. unstrukturierten sowie schnelllebigen Datenmengen. Die gesammelten Daten können dabei aus verschiedensten Quellen stammen, werden größtenteils in Rohform gespeichert und zum Zweck der Visualisierung, Analyse und Data Mining bzw. Machine Learning verwendet.
In der ursprünglichen Definition von Big Data bezieht sich das „Big“ auf die drei V‘s:
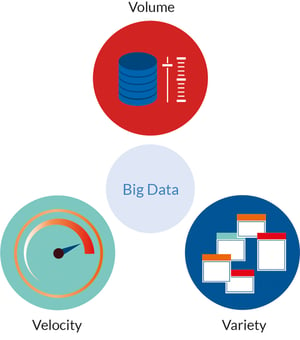
1. Volume (Datenvolumen)
Sehr große Datenmengen können verarbeitet und gespeichert werden.
2. Velocity (Geschwindigkeit)
Daten werden in kürzester Zeit und mit hoher Geschwindigkeit, nahezu in Echtzeit, verarbeitet.
3. Variety (Bandbreite der Datentypen und -quellen)
Daten unterschiedlichster Typen und Herkunft werden verarbeitet. Sie können strukturiert (relationale Datenbanken), semi-strukturiert (CSV, Logs, XML, JSON), unstrukturiert (zum Beispiel Mails, Dokumente wie PDF, DOCX) und binär (Bilder, Video, Audio) sein. Somit ist auch die Anbindung von Systemen wie Social Media, Web Tracker und Web-Suche möglich.
In einem folgenden Beitrag gehen wir auf die Unterschiede und Gemeinsamkeiten beider Welten ein.
Der Unterschied zwischen Data Warehouse und Big Data
Data Warehouse und Big Data – Grundpfeiler eines modernen Data Hubs– Teil 2







MID Blog Newsletter abonnieren