
Data Warehouse und Big Data –
Grundpfeiler eines modernen Data Hubs - Teil 2
Unter dem Motto – „Data Warehouse und Big Data – Grundpfeiler eines modernen Data Hubs“ – stellen wir Ihnen hier diese beiden Lösungen vor. Neben einer Gegenüberstellung der Unterschiede beider Welten, erhalten Sie auch eine Nutzendarstellung. Ziel ist es, das „Warum“ und „Wofür brauche ich welche Ansätze“, zu liefern.
Dies ist der zweite Teil der Serie. In diesem Artikel geht es um die Unterschiede zwischen Data Warehouse und Big Data-Lösungen.
Beide Lösungen haben durchaus Gemeinsamkeiten wie z.B. die Verwaltung großer Datenmengen und deren Verwendung im Reporting. Dennoch gibt es einige wichtige Unterschiede, die in dieser Tabelle übersichtlich dargestellt werden.
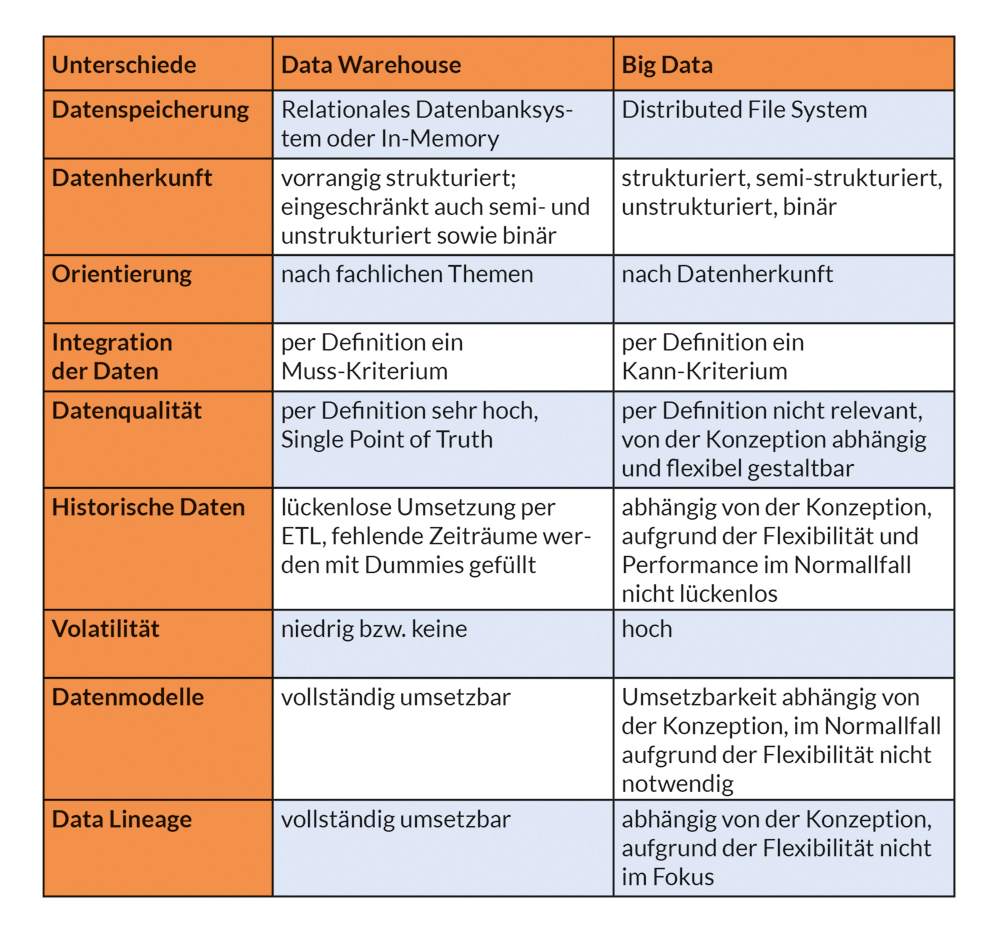
Datenspeicherung
Beim klassischen DWH werden die Daten in einem relationalen Datenbanksystem gespeichert. Sie werden strukturiert und gruppiert in Tabellen und Spalten gleichen Typs abgelegt. Eine entsprechende Gleichheit der Daten muss vorliegen. Geschwindigkeit und maximale Datenmenge ist vom verwendeten Datenbankhersteller abhängig. Performanceoptimierungen können mittels unterschiedlicher Technologien, zum Beispiel in-memory und Massive Parallel Processing (MPP), erzielt werden. Die Erweiterbarkeit solcher Systeme ist jedoch an physische Grenzen gebunden.
Bei Big Data hingegen werden verteilte Dateisysteme (DFS – Distributed File System) verwendet. Diese verarbeiten die Daten, in dem sie als kleine Dateien verteilt in einem Rechner-Cluster gespeichert und verwaltet werden. Solche Cluster lassen sich in puncto Geschwindigkeit und Datenmenge beliebig erweitern.
Datenherkunft
Da beim klassischen DWH die Daten strukturiert in einem relationalen Datenbanksystem gespeichert werden, können nur Daten aus Datenquellen verarbeitet werden, die die Daten strukturiert bereitstellen. Dies sind z.B. operative Systeme, die ebenfalls relationale Datenbanksysteme verwenden. Semi- bzw. unstrukturierte Daten können teilweise in strukturierte Daten umgewandelt werden, um sie zu laden. Dies ist jedoch mit erhöhtem Aufwand verbunden. Moderne relationale Datenbanksysteme bieten auch die Möglichkeit, semi- und unstrukturierte Daten ohne Umwandlung in strukturierte Daten zu speichern. Dies ist für manche Anwendungsfälle zwar sinnvoll, widerspricht aber dem Grundsatz der Integrität der DWH Definition.
Big Data und die Verwendung der Dateisystemspeicherung bietet die Möglichkeit, alle Formen von Daten zu verarbeiten und zu speichern (strukturiert, semi-strukturiert, unstrukturiert, binär).
Orientierung
Im DWH werden die Daten nach fachlichen Themen (Kunde, Produkt, …) organisiert, gespeichert und integriert.
Bei Big Data orientiert sich die Organisation der Daten an der Datenherkunft bzw. den Quellsystemen.
Integration der Daten
Die Integration der Daten, also die Verknüpfung von Daten unterschiedlicher Herkunft, spielt im klassischen DWH eine wichtige Rolle. Hierzu werden ETL-Prozesse verwendet.
In Big Data Systemen ist die Integration der Daten zweitrangig und wird meist nicht durchgeführt. Die Datenbeladung erfolgt mittels ELT- bzw. Data Ingest Lösungen.
Datenqualität
Beim DWH sind die Anforderungen an die Datenqualität hoch. Insbesondere wenn es sich um rechtssichere, buchhalterische Berichte handelt, müssen die Daten sehr genau sein. Die Verwendung des DWH als „Single Point of Truth“ setzt voraus, dass die Daten 100% korrekt sind.
Bei Big Data ist die Anforderung an die Datenqualität deutlich niedriger. Hier arbeitet man mit Werten, die sich wegen der hohen Datenmengen an die Realität annähern. Unschärfen werden in Kauf genommen bzw. statistisch entschärft. Der Businessnutzen der Daten wird über die Qualität gestellt.
Historische Daten
Die großen Datenmengen in einem DWH entstehen vor allem durch das Speichern über große Zeiträume sowie deren Veränderungen. Diese Veränderungen bilden einen hohen Mehrwert für den klassischen DWH-Ansatz sowie deren Analyse.
Bei Big Data wird die Datenmenge durch die Quellsysteme bestimmt. Die Speicherung von historischen Veränderungen ist je nach Datenbasis möglich aber kein vorrangiges Ziel.
Beständigkeit
In einem DWH sollen keine Daten gelöscht werden. Dies ist unter anderem notwendig, um die Historie der Daten aufrechtzuerhalten.
Bei Big Data besteht diese Anforderung genauso. Allerdings wird sie wegen geringerer Qualität und unstrukturierter Sammlung von Daten sowie meist kürzerer Auswertungszeiträume weniger strikt gehandhabt. Gelegentlich macht ein Löschen der „alten/schlechten“ Daten sogar Sinn, um die Ergebnisse bei Data Mining oder Machine Learning Prozessen zu verbessern. Über die letzten Jahre haben sich viele Data Lakes in einen wahren Datenfriedhof verwandelt, der zwangsweise aufgrund hoher Datenmengen und damit verbundenen steigenden Kosten für Speicherplatz zu Datenlöschungen führt.
Datenmodelle
Im DWH werden die Daten strukturiert in einem Datenbanksystem abgelegt. Diese Struktur unterliegt klaren Regeln und ermöglicht es, einheitliche Datenmodelle zu erstellen. Diese Datenmodelle, zum Beispiel Data Vault und Star- / Snowflake-Schemata haben sich über die letzten Jahrzehnte etabliert und bieten ausgereifte Lösungen. Weiterhin sind diese Modelle normiert und somit allgemein leicht nachzuvollziehen und zu verstehen.
Da Big Data neben strukturierten auch semi-strukturierte, unstrukturierte und binäre Daten beinhaltet, ist eine Modellierung der Strukturen sehr schwierig und mit hohem Aufwand verbunden. Eine umfängliche Datenmodellierung steht der Flexibilität, die Big Data in puncto Quelldaten bietet, entgegen. Ansätze und Lösungen stecken hier noch in den Kinderschuhen, sind aus fachlicher Sicht im Normallfall aber auch nicht notwendig.
Data Lineage
Die klaren Regeln bei der Modellierung im klassischen DWH erlauben es über die Metadaten die Abhängigkeiten der Objekte und den Datenfluss nachzuvollziehen. Dies kann für Anpassungen am System sowie Audit-Fähigkeiten hilfreich sein. Die Data Lineage kann hierbei auch den Informationsraum der Daten verlassen und zum Beispiel Prozesse inkludieren. Sie ist für einige regulatorische Anforderungen, wie BCBS239 (Basel Committee on Banking Supervision's standard number 239) oder die DSGVO (Datenschutz Grundverordnung) unumgänglich.
Da eine Modellierung in Big Data eher hinderlich ist, fehlt die Möglichkeit, solche Abhängigkeiten und Datenflüsse in der Gesamtheit der Daten zu dokumentieren und nachzuvollziehen. Mit speziellen Methoden (Machine Learning, etc.) kann man näherungsweise Rückschlüsse auf Zusammenhänge und Abhängigkeiten ermitteln.
Vorangegangener Beitrag:
Was ist Data Warehouse? Was ist Big Data?
Data Warehouse und Big Data – Grundpfeiler eines modernen Data Hubs– Teil 1
Folgebeitrag:
Nutzen und Zielrichtung von Data Warehouse und Big Data
Data Warehouse und Big Data – Grundpfeiler eines modernen Data Hubs– Teil 3







MID Blog Newsletter abonnieren