
Modellierung der Eingangs- und Ausgangs-Datenstrukturen sowie der Datentransformation
Was wir bisher zu dem Thema veröffentlicht haben finden Sie hier:
Teil 1 - Teil 2 - Teil 3 - Teil 4 zu Model Driven Transformation for Streaming Applications
In diesem Betrag beschäftigen wir uns mit der Struktur des innovator-Modells, aus dem die Datentransformationsregeln generiert werden sollen.
Die Challenge/Vision:
IT-Systeme haben in der Regel an ihren Schnittstellen unterschiedliche Datenstrukturen und -typen für ein und dasselbe fachliche Objekt. Sollen Daten zwischen zwei IT-Systemen übertragen werden, müssen sie deshalb transformiert werden. Nachdem Schnittstellen nur selten mit Modellen dokumentiert sind, werden die Datentransformationsregeln für die Übertragung meistens manuell erfasst und statisch programmiert. Das ist aufwendig und fehleranfällig.
Unsere Aufgabe ist es nun die Eingangs- und Ausgangs-Datenstrukturen mit dem innovator zu modellieren, die Attribute des Quell-Systems denen des Ziel-Systems zuzuordnen und daraus die Datentransformationsregeln zu generieren. Das hierfür entworfene innovator-Modell gliedert sich in mehrere Hauptbestandteile:
Startpunkt ist ein logisches, kanonisches Datenmodell, welches die Gesamtsicht auf die relevanten Datenstrukturen aus Sicht der Fachabteilungen abbildet. Wir nutzen dafür das UML-Klassenmodell mit Klassen, Attributen und Assoziationen.
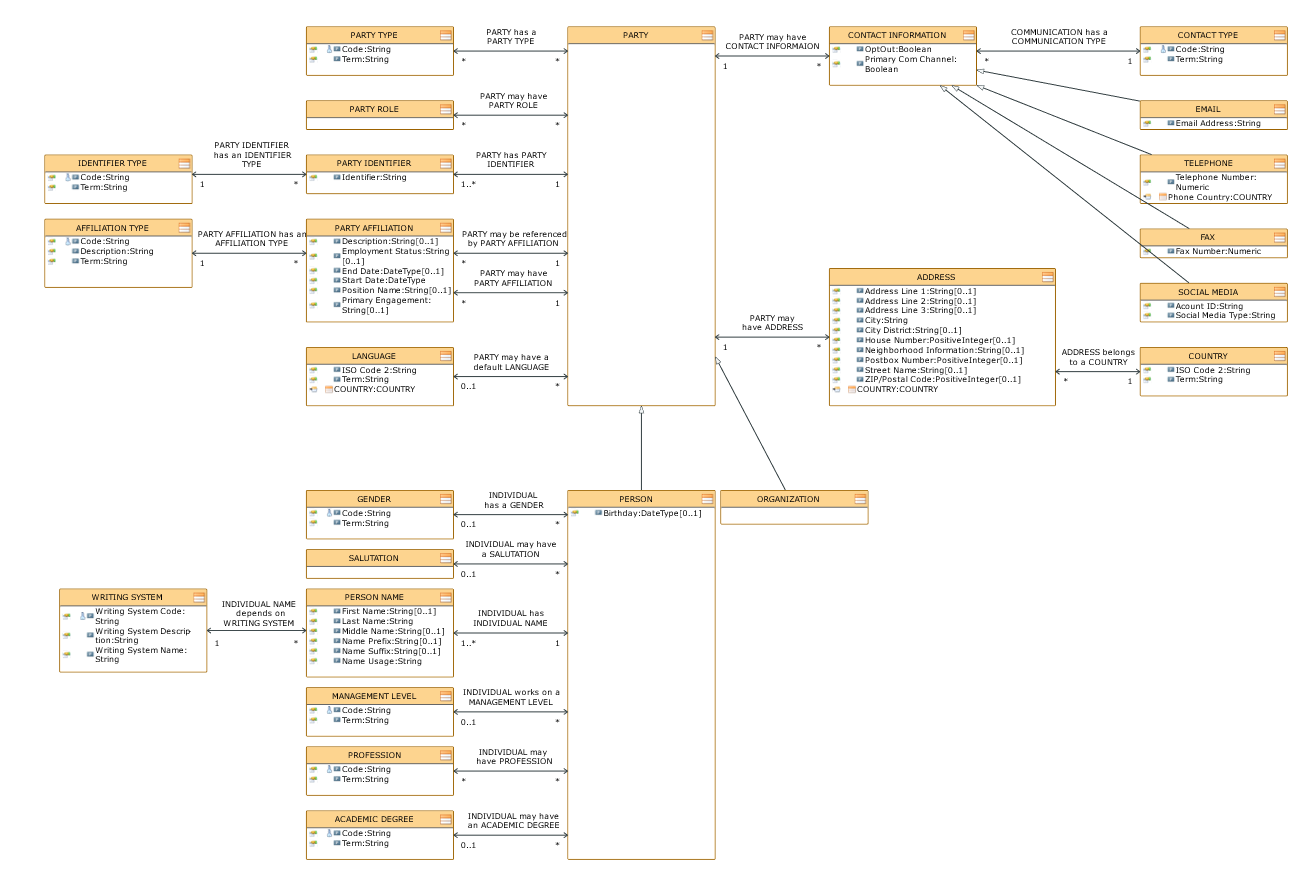
Abb.1: Ausschnitt aus dem logischen Datenmodell (Zielstruktur)
Für die Quell- und Zielsysteme wird jeweils ein physisches Datenmodell erstellt. Es bildet die Datenstrukturen incl. Angabe technischer Datentypen und Default-Werten des jeweiligen IT-Systems ab. Auch hier nutzen wir ein UML-Klassenmodell mit technischen Zusatzinformationen.
Für den Aufbau der Schnittstellen (Producer, Consumer) werden eigene Schnittstellendiagramme angelegt, deren Klassen und Attribute, Ausschnitte aus den physischen Datenmodellen der Quell- und Zielsysteme sind.
Das Mapping zwischen den Datenmodellen erfolgt auf Attributebene mit Hilfe von Dependencies. Jedes relevante Quellattribut muss also im Modell mit dem passenden Zielattribut verbunden werden. Es wurden dazu jeweils eine eigene Dependency für 1:1 Mapping und N:1 Mapping definiert um diese Fälle unterscheiden zu können.
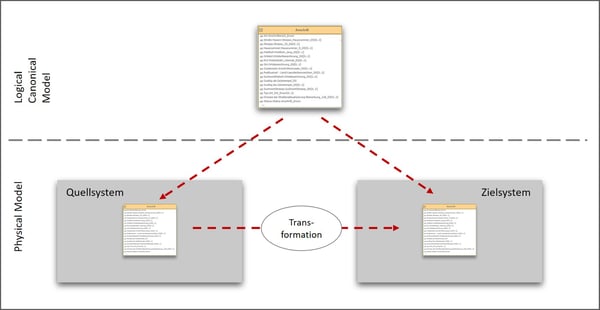
Abb.2: Schematischer Aufbau des innovator-Modells
Jedes Schnittstellendiagramm definiert mit seinen Klassen und Attributen den Scope genau einer Schnittstelle. Daneben existiert in jedem Schnittstellendiagramm ein Root-Element, welches den Einstieg in die Datenstruktur der Schnittstelle bildet.
Nachdem das physische Modell alle Implementierungsdetails enthält muss der Generator nur die Inhalte der Schnittstellendiagramme auslesen um vollständige Schnittstellen in der Swagger-API oder in XSD generieren zu können.
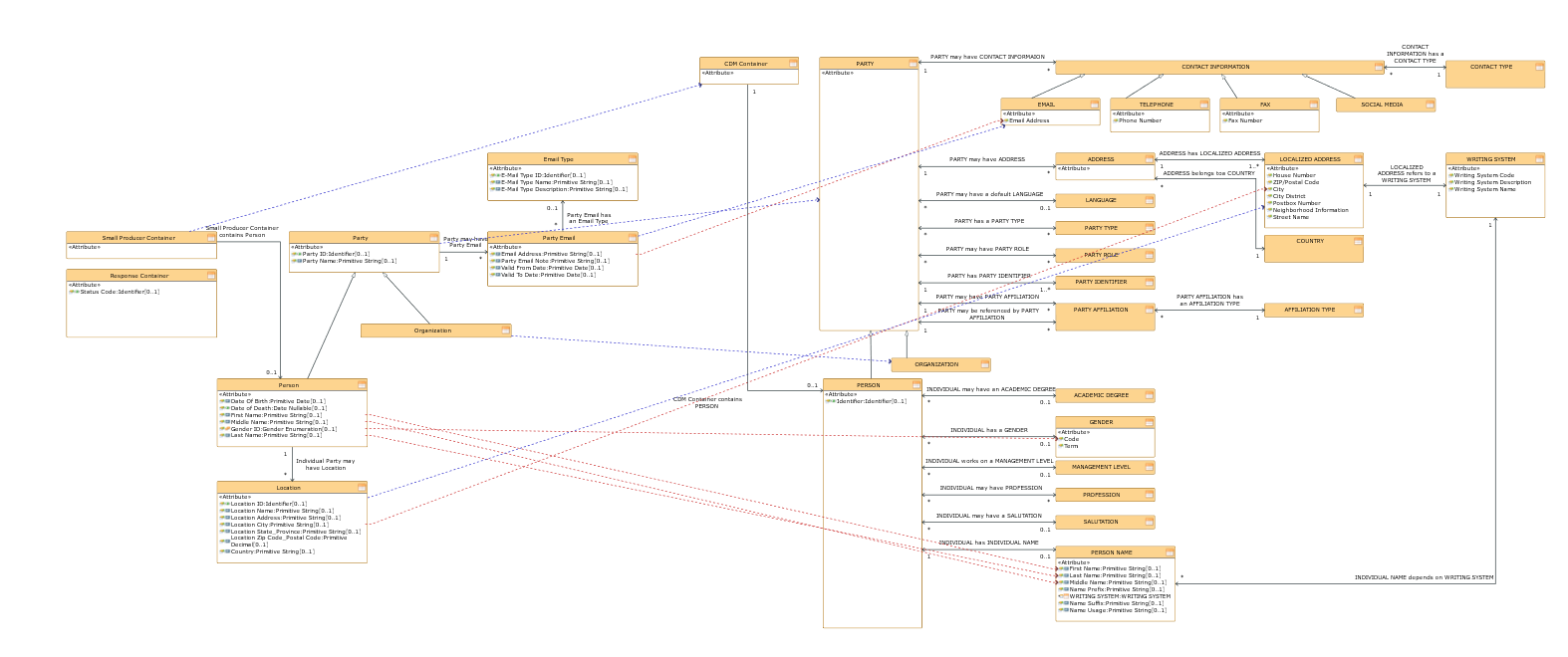
Abb.3: Schnittstellendiagramm mit Anzeige der Mapping-Dependencies
In unserem Beispielmodell haben wir vier Mappingvarianten definiert, welche die Grundlage für die Transformationregeln des Generators bilden:
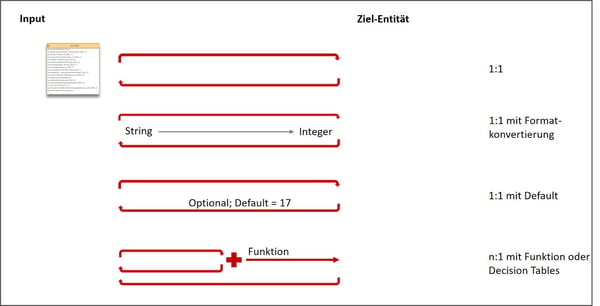
Abb.4: Varianten für Mapping und Transformation auf Attributebene
1:1 Mapping ohne Konvertierung:
Entspricht der Datentyp des Quellattributes dem des Zielattributes, dann wird der Inhalt ohne Konvertierung übertragen werden.
1:1 Mapping mit Format-Konvertierung:
Sobald die Datentypen von Quelle und Ziel unterschiedlich sind, muss der Stream-Prozessor den Inhalt eines Feldes entsprechend konvertieren.
1:1 Mapping mit Default:
Falls bei der Übertragung eines Attributes kein Inhalt geliefert wird, muss der Stream-Prozessor den Default-Wert des Zielattributes übertragen bzw. ergänzen.
N:1 Mapping mit Funktion oder Decision Tables:
Die komplexeste Variante des Mappings benötigt zusätzlich zur Dependency eine Beschreibung der spezifischen Transformationsregeln. Je nach Anforderung kann die Funktion in einer vorher festgelegten Sprache beschrieben werden. Oft kann eine Transformationsregel auch mit Hilfe einer Decision Table (unter Verwendung von Decision Model and Notation) beschrieben werden.
Das Modell muss also in erster Linie um die Verbindung von Quellattributen zu Zielattributen ergänzt werden. Angereichert werden diese um die Definition des Umfanges jeder Schnittstelle mit Hilfe des jeweiligen Schnittstellendiagramms.
Nur für den komplexesten Fall, mit Funktionen und/oder Dicision Table, sind noch zusätzliche Informationen notwendig um die jeweilige Transformationsregel zu beschreiben.
Aus einem derart vorbereiteten Modell kann nun ein extra für unser Projekt erstelltes innovator-Generator-Plugin die Datentransformationsregeln generieren.
Weiterlesen:
Der folgende Blog-Beitrag beschäftigt sich mit den Werkzeugen und der Entwicklungsumgebung, welche neben dem aktuellen innovator benötigen werden.







MID Blog Newsletter abonnieren