
Die IT-Landschaft von heute muss sich immer wieder und dazu noch in immer kürzeren Zeitabschnitten an die wachsenden Datenmengen anpassen. Wir schreiben keine Nachrichten mehr, sondern übertragen Voice Messages, hören on Demand Musik über Streaming-Anbieter und schauen Video-On-Demand auf dem Fernseher und von unterwegs. Neue Fahrzeuge haben das Potential bei einem Unfall direkt Kontakt mit der Versicherung für Schadensmeldung aufzunehmen und selbst unser Kühlschrank könnte schon leer gewordene Lebensmittel selbständig nachbestellen. Zudem kommt hinzu, dass dieses Meer an Daten in „Echtzeit“ analysiert, verarbeitet und weitertransportiert werden muss.
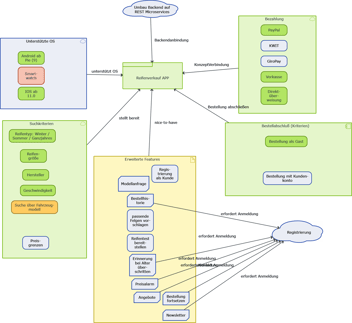
Bei der Frage welche Software Architektur für diese Herausforderungen die Richtige ist bzw. welche Komponenten am besten in meine bestehende IT-Landschaft passen, stößt man heutzutage sehr schnell auf die Streaming Architektur und um es noch stärker einzugrenzen auf die Kappa Architektur mit ihrem populärsten Vertreter, der Streaming Plattform Apache Kafka.
Die Challenge:
Wir, ein kleines Team aus erfahrenen Software Architekten und Entwicklern innerhalb der MID GmbH, wollen uns im Rahmen eines Projektes diese Streaming Plattform näher anschauen und auf Herz und Nieren erproben.
Als Herausforderung soll neben dem reinen Datentransport als Anwendungsbeispiel ein Stream-Processing implementiert werden, bei dem Eingangs-Datenstrukturen in Ausgangs-Datenstrukturen umgewandelt werden. Wir als „the modeling company“ wollen die benötigten Datenstrukturen und die Datentransformation natürlich mit unserer aktuellen Version des Innovators modellieren. Danach sollen aus dem Modell die Datentransformations-Regeln für den Stream-Processor generiert werden - natürlich immer mit dem Blick auf Kosten und Aufwand!
Mit dem System, das wir hier aufbauen wollen, wird folgendes möglich sein:
- Nutzung von Apache Kafka als zentrale Data Communication Plattform.
- Zur Laufzeit:
- Ein Quell-System erzeugt Daten, die an Kafka gesendet werden.
- Diese Eingangs-Daten liest der Stream-Processor und transformiert sie zu Ausgangs-Daten, die er wieder an Kafka sendet.
- Ein Ziel-System liest die Ausgangs-Daten.
- Im Innovator:
- Modellierung der Eingangs- und Ausgangs-Datenstrukturen sowie der Daten-Transformation.
- Generierung der Datentransformationsregeln für den Stream-Processor.
- Nutzen:
- Bei Änderung der Transformationsregeln ist keine Änderung der Programmierung des Stream-Processor notwendig, da seine Funktion ausschließlich von den Datentransformationsregeln gesteuert wird.
Die Lösung hätte sehr großes Potential da:
- Der Transport und die Konvertierung von Daten für alle Unternehmen eine Herausforderung darstellt.
- Mit KAFKA eine erprobte hoch performante Lösung mit Persistenz verfügbar ist.
- Ausschließlich das Modell die Basis der Datentransformationsregeln ist.
Wie es weitergeht:
In regelmäßigen Abständen werden wir über den Verlauf unseres Projektes weitere Blogs verfassen. Geplant sind insgesamt 9 Blogs, die sich im Rahmen unseres Projekts jeweils einem Teilaspekt widmen. Wir würden uns freuen, wenn Sie unserer Geschichte folgen und den Blog weiterempfehlen würden. Auch freuen wir uns über Ihr Feedback.
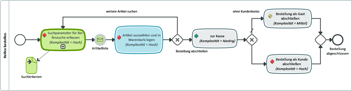
Teil 2: Fachliches Integrationsszenario und Lösungsansatz mit Kafka
Teil 3: Apache Kafka – Funktionsweise, Doku, API
Teil 5: Modellierung der Eingangs- und Ausgangs-Datenstrukturen sowie der Datentransformation
Teil 6: Unser Labor - Einrichtung der Entwicklungsumgebung
Teil 7: Producer und Consumer - die Anbindung der Systeme
Teil 8: Datentransformation vom Producer zum Consumer
Teil 9: Generator für die Abbildungsvorschrift von Datenstrukturen







MID Blog Newsletter abonnieren