
Künstliche Intelligenz oder irgendwas mit neuronalen Netzen
Künstliche Intelligenz hat es als Gesprächsstoff inzwischen sogar in die Politik und in die Feuilletons der Zeitungen geschafft, wo insb. die gesellschaftlichen Auswirkungen dieser neuen Technologien diskutiert werden. Da häufig neuronale Netze eine beliebte Technologie sind, mit denen künstliche Intelligenz erklärt wird, bleibt bei den Lesern das Bild eines nachprogrammierten Gehirns haften, was entsprechende Emotionen wie Angst oder Ungewissheit weckt.
Dabei sind neuronale Netze nur ein Ansatz für das sogenannte maschinelle Lernen (Englisch: Machine Learning). Hierbei lernt ein Algorithmus aus Beispielen, also historischen Daten, und kann diese nach Beendigung der Lernphase verallgemeinern, und damit auf neue, unbekannte Daten wieder anwenden. Dabei werden oft auch schon seit Jahrhunderten bekannt statistische Verfahren wie z.B. die lineare Regression angewendet.
Neben der eigentlichen Extraktion, Aufbereitung und Analyse der Daten bietet maschinelles Lernen die Möglichkeit, Zusammenhänge zwischen den Daten in Algorithmen auszudrücken und zu nutzen. Die Vorteile maschinellen Lernens gegenüber von Menschen programmierten Algorithmen werden mit der derzeitigen Entwicklung der Datenquellen in den Unternehmen begünstigt. Im Big-Data-Zeitalter stehen Unternehmen in Qualität und Quantität ausreichend Daten zur Verfügung, um diese zu analysieren und algorithmische Zusammenhänge sicher zu erkennen.
Wie funktioniert maschinelles Lernen (Machine Learning)?
Beim maschinellen Lernen handelt es sich um einen algorithmischen Ansatz, um spezifische Problematiken mittels des „Trainings“ von diversen Algorithmustypen oder -vorlagen zu lösen. Dabei werden die Vorlagen, wie z.B. die neuronalen Netze, durch die Daten trainiert, d.h. automatisiert angepasst. Maschinelles Lernen kann in die zwei Bereiche überwachtes und unüberwachtes Lernen unterteilt werden. Übersichtlich kann die Kategorisierung maschineller Lernverfahren wie folgt vorgenommen werden:
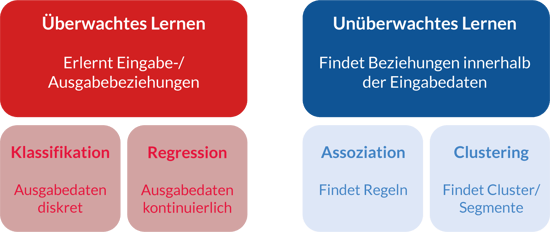
In der Praxis hat vor allem das überwachte Lernen besondere Relevanz. Hierbei wird die Input-Output-Beziehung modelliert. Im Folgenden werden einfache Beispieldaten für die Anwendung einer einfachen Regression mit einer kontinuierlichen Zielvariablen dargestellt:

Anhand historischer Daten wird die Beziehung zwischen Einnahmen und Ausgaben der Kunden sowie des jeweiligen Kreditrisikos erlernt. Das erstellte Modell kann das Kreditrisiko für neue Kunden berechnen. Dabei handelt es sich um ein Regressionsmodell.
Bei der Klassifikation wird eine Kategorie vorhergesagt (z.B. männlich, weiblich). Bei der Assoziation werden Regeln innerhalb der Eingabedaten gefunden (z.B. Kunden, die Bier kaufen, kaufen auch Chips). Mittels Clustering können Segmente/Ansammlungen innerhalb der Daten hinsichtlich gesuchter Eigenschaften definiert werden (z.B. Kundensegmente).
Einfach nur Algorithmen auf Daten anwenden oder braucht es mehr?
Daten sind natürlich der zentrale „Rohstoff“ im maschinellen Lernen. Allerdings beschränken sich sowohl das Vorgehen als auch das Wissen nicht auf die Datenanalyse und die Konstruktion eines maschinellen Algorithmus. Was auf den ersten Blick so einfach erscheint, ist ein Prozess, bei dem mit verschiedenen Algorithmen experimentiert wird und Variablen angepasst werden. Zudem müssen in der Regel Datenvorbereitungsschritte, wie z.B. Datenstandardisierungen oder das Einfügen von fehlenden Werten, durchgeführt werden, um ein funktionierendes Machine-Learning-Modell zu erstellen. Die zentrale Herausforderung ist es, die Stellschrauben bei Daten und Algorithmus so zu drehen, dass ein erlerntes Modell die Trainingsdaten weder auswendig lernt, und damit potenziell bei der Anwendung neuer Daten falsch liegt, noch zu sehr generalisiert, und damit zu ungenau arbeitet.
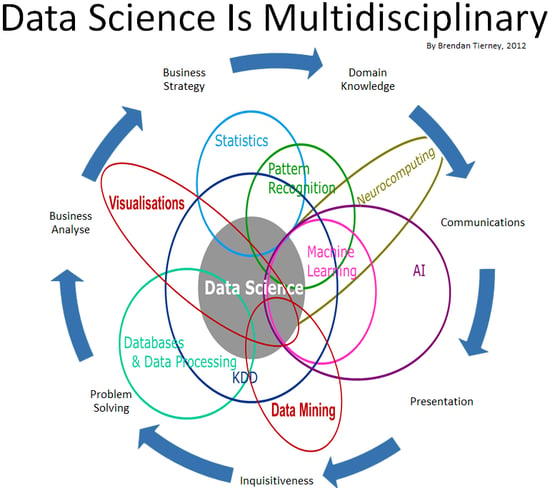
Bei der korrekten Auswahl der Stellschrauben ist nicht nur die Datenbeschaffenheit relevant, sondern auch der Kontext von Geschäftsstrategie und Fachdomäne. Diese müssen vorab geklärt und aufbereitet werden. Dann kann man die richtigen Fragen stellen, die die Daten „beantworten“ sollen. D.h. neben der analytischen Tätigkeit muss klar und auf Augenhöhe mit den Fachabteilungen kommuniziert werden. Diese komplexe Tätigkeit verdeutlicht das folgende Schaubild:
Ist ein effektiver Algorithmus auf Basis der Trainingsdaten gefunden worden, muss dieser in die IT-Produktionsumgebungen des Unternehmens integriert werden, um dann, „gefüttert“ mit den Live-Daten, tatsächlich seine Wirkung zu entfalten. Hier ist eine Verbindung mit automatisierbaren Prozess- und Entscheidungsmodellen ratsam und vorteilhaft: Es ist ein bevorzugter Anwendungsfall maschinellen Lernens, Entscheidungen in Geschäftsprozessen zu automatisieren. Z.B. könnte in einem Kreditbearbeitungsprozess über die Kreditwürdigkeit eines Kunden befunden werden und der Prozess gesteuert werden. Neben der transparenten Darstellung des Zusammenhanges zwischen Prozess und Algorithmus auf fachlich-konzeptioneller Ebene wird auch technisch die Ausführung des Algorithmus zum richtigen Zeitpunkt und die Bereitstellung der benötigten Daten gelöst.
In einem folgenden Beitrag werden wir Ihnen konkret zeigen, wie mittels der Workflow-Engine von Camunda maschinelles Lernen „zum Leben“ erweckt wird.






MID Blog Newsletter abonnieren